
聚力名企共建课程,联合培养高端人才
传智教育与百度云平台、帆软、北京大数据研究院共同研发实战型大数据课程,并持续为课程输入高端大数据技术
-
百度云是中国最大的云计算平台之一,与传智教育共同制定和推广大数据人才标准及人才培养方案,为大数据时代下未来教育的新体验起到了促进和推动作用
-
帆软领衔中国BI,荣获“中国BI市场年度占有率第一”,与传智教育强强联手,开发BI专题课程,对 BI 工具的定义进行了重新梳理,并且从生态的角度描述了 BI 生态系统
-
北京大数据研究院由中关村管委会、海淀区政府、北京大学、北京工业大学四方共同支持建立,与传智教育联手共建互联网、政务、医疗等行业课程
八大核心优势,精心锻造大数据学科
-
大规模集群部署调优
-
全方位布局数据中台
-
大数据Python生态圈
-
大数据课程占比80%
-
多行业大型实战项目
-
高级软件工程师课程
-
IT行业标杆讲师团队
-
独家Tlias教学系统

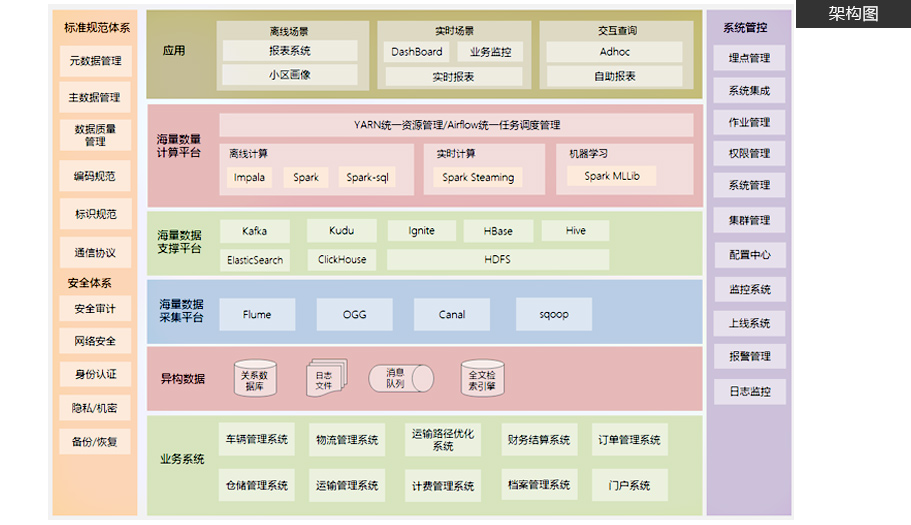
02.全方位布局数据中台 完善“企业级”技能
DATA CENTER

● 参考阿里的数据中台构建理论,设计数据资产化、创新敏捷化,平台智能化、服务产品化等核心因素
● 涵盖大数据计算服务、大数据开发套件、数据主题域仓库、元数据管理、数据地图、系统分析、影响域分析、主数据、数据治理、数据服务引擎及数据可视化等内容
● 手把手教会学员如何搭建数据中台,学习通过数据技术,对海量数据进行采集、计算、存储、加工,同时统一标准和口径
03.大数据Python生态圈 PySpark/PyFlink/Alink
PYTHON
掌握大数据数据挖掘技术,提高多业务场景解决数据挖掘问题能力,
培养数据分析与挖掘核心竞争力,实现全栈大数据开发
-
PySpark技术栈
如何从大数据中发现和提取有价值的数据,使用数据挖掘SparkMI&MLlib等技术,达到数据价值化目标,助力于关键业务问题解决 -
PyFlink技术栈
通过ALink(Flink机器学习)达到数据价值化目标,同时利用TensorflowOnFlink解决深度学习能力,为学员在大数据+AI领域助力 -
数据科学全流程建模分析
从大数据数据采集、数据ETL、数据分析及机器学习建模构建全流程Pipeline,助力学员成为大数据高端人才
04.覆盖核心技能 大数据课程占比80%
CORE SKILLS


- 大数据
基础体验课 - Java语言编程
- Hadoop技术栈
- 后端数据微服务
接口开发 - NoSQL存储
- Flink技术栈
- Spark技术栈
-
主讲内容
• Linux操作系统
• MySQL数据库
• Kettle数据预处理
• Apache Superset可视化开发
• 电商运营指标分析可掌握的核心能力
1、掌握企业级ETL平台的kettle;
2、掌握BI的可视化平台Superset;
3、掌握kettle流式数据ETL处理设计思想;
4、掌握大数据企业开发中最常见的的linux的操作;
5、掌握一款主流数据库管理工具DataGrip;
6、掌握企业MySQL的调优方案;
7、掌握大数据分析中数据全量及增量同步解决方案;
8、掌握生产环境中数据分析程序的部署解决方案。 -
主讲内容
• 编程基础
• 面向对象
• 常用类
• 集合操作
• IO操作
• Java基础增强
• 爬虫案例可掌握的核心能力
1、掌握Java程序基础数据类型;
2、掌握开发中常用类如集合、IO流、常用类等操作;
3、掌握Java异常处理机制;
4、掌握反射、网络编程、多线程开发;
5、掌握Jsoup的网络爬虫开发;
6、掌握JDBC数据库连接操作;
7、掌握ETL数据处理和BI报表开发 。可解决的现实问题
具备JavaSE开发能力。
-
主讲内容
• Linux操作系统高级
• 大数据基础和硬件介绍
• Zookeeper
• HDFS
• MapReduce
• Yarn
• Hive可掌握的核心能力
1、掌握Shell命令;
2、掌握zookeeper原理并应用;
3、掌握HDFS的使用和MapReduce编程;
4、理解MapReduce原理和调优
5、掌握Yarn的原理和调优;
6、掌握Hive的使用和调优。可解决的现实问题
具备Hadoop开发能力、离线数据仓库开发能力。
-
主讲内容
• Spring
• Spring Boot
• Spring Cloud
• Spring Cloud搜索案例可掌握的核心能力
1、掌握SpringBoot整合SpringMVC开发;
2、掌握SpringBoot整合MyBatis开发;
3、掌握Eureka搭建;
4、掌握Feign的使用。可解决的现实问题
具备后端数据微服务接口开发,可胜任通过Spring技术架构完成微服务搭建。可完成企业级数据微服务接口开发。
-
主讲内容
• Redis存储
• HBase存储
• ELK可掌握的核心能力
1、掌握Redis原理及架构;
2、掌握Redis命令操作、数据结构;
3、掌握Hbase原理及架构;
4、掌握HBase命令操作、MapReduce编程;
5、掌握Phoneix二级索引优化查询;
6、掌握ELK开发。可解决的现实问题
具备使用Hbase和Redis开发调优能力、ELK海量数据处理能力。
-
主讲内容
• Kafka
• Flink流式计算
• Flink批处理
• Flink Core
• Flink SQL
• Flink综合案例可掌握的核心能力
1、掌握Kafka原理及架构;
2、掌握KafkaStreams开发;
3、掌握基于Flink进行实时和离线数据处理、分析;
4、掌握基于Flink的多流并行处理技术;
5、掌握千万级高速实时采集技术。可解决的现实问题
具备Kafka消息队列开发和调优能力、Flink流式和批量数据开发能力。
-
主讲内容
• Scala语言
• Spark core
• Spark sql
• SparkStreaming
• Structure streaming/p>可掌握的核心能力
1、掌握Scala语言基础、数据结构;
2、掌握Scala语言高阶语法特性;
3、掌握Spark的RDD、DAG、CheckPoint等设计思想;
4、掌握SparkSQL结构化数据处理,Spark On Hive整合;
5、掌握SparkStreaming整合Kafka完成实时数据处理;
6、掌握SparkStreaming偏移量管理及Checkpoint;
7、掌握StructureStreaming整合多数据源完成实时数据处理。可解决的现实问题
具备Spark全栈开发能力,满足大数据行业多场景统一技术栈的数据开发,提供就业核心竞争力。
05.多行业大型实战项目 完整还原真实业务场景
PROJECTS
“大厂级”深度项目
基于热门行业领域
联合专家顾问团
研发“大厂级”深度项目
基于企业真实项目
企业真实项目
拒绝项目DEMO
拒绝脱离市场需求
多行业大型项目
项目实战占比超40%
涵盖电商、证券、物流、
教育、出行等行业
企业真实研发环境
置身其中
体验真实企业研发环境
为进入企业提前准备
-
今日指数证券
-
星途车联网
-
客快物流
-
知行教育
-
智数电商
-
千面电商
-
天知票务反爬虫
-
蜂鸟DMP广告分析
-
万网信号
-
项目简介
实时监控证券市场的市场每日的业务交易,实现对证券市场交易数据的统计分析
搭建监察预警体系,包括:预警规则管理,实时预警,历史预警,监察历史数据分析等
股市行情交易数据实时采集、实时数据分析、多维分析,即席查询,实时大屏监控展示项目特色
◆ 高性能处理,流处理计算引擎采用的是Flink,实时处理100万笔/s的交易数据
◆ 基于企业主流的实时流处理技术框架:Flume、Kafka、Flink、Hbase等
◆ 基于ELK的批业务数据处理,可进行大数据量多维分析
◆ Hbase5日内秒级行情亿级规模,MySQL5日内分时行情千万级规模
◆ T-5日内实时行情响应耗时毫秒级,T-5日外的历史行情响应耗时秒级 -
-
项目简介
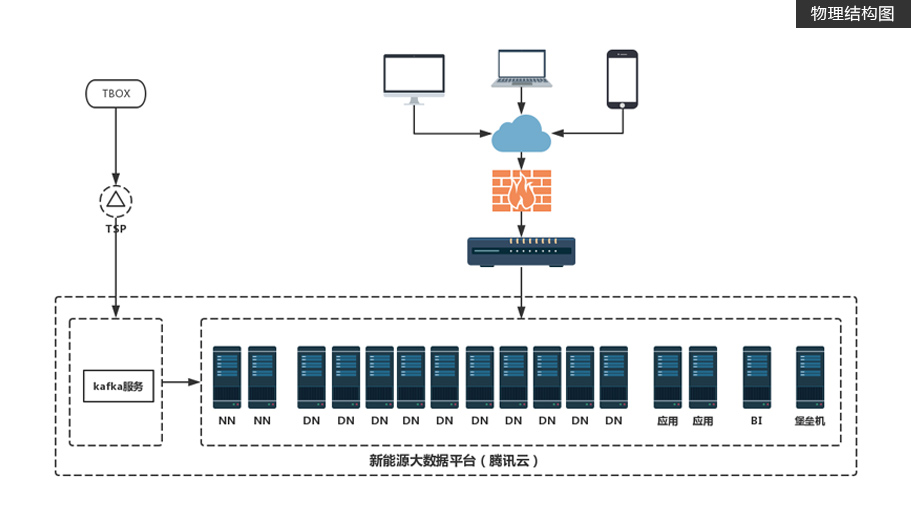
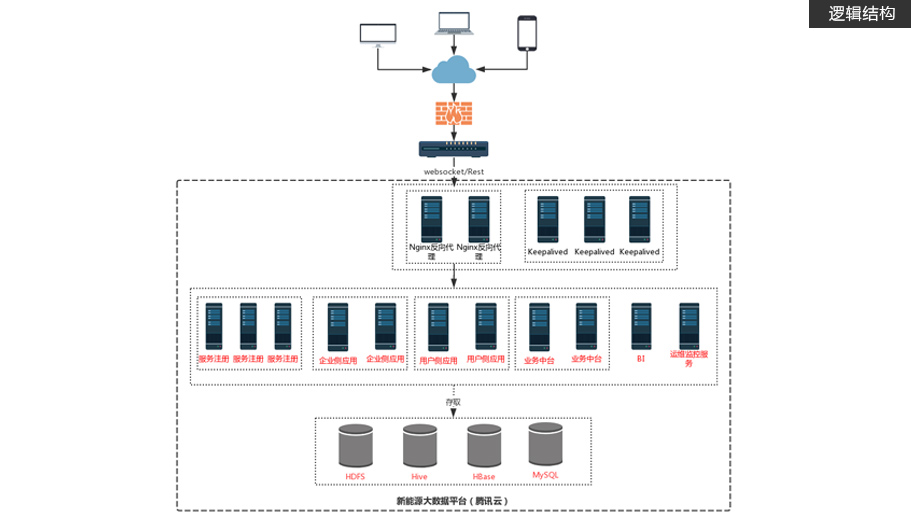
涵盖完整车联网业务场景,包含驾驶行程、电子围栏、远程诊断等真实业务
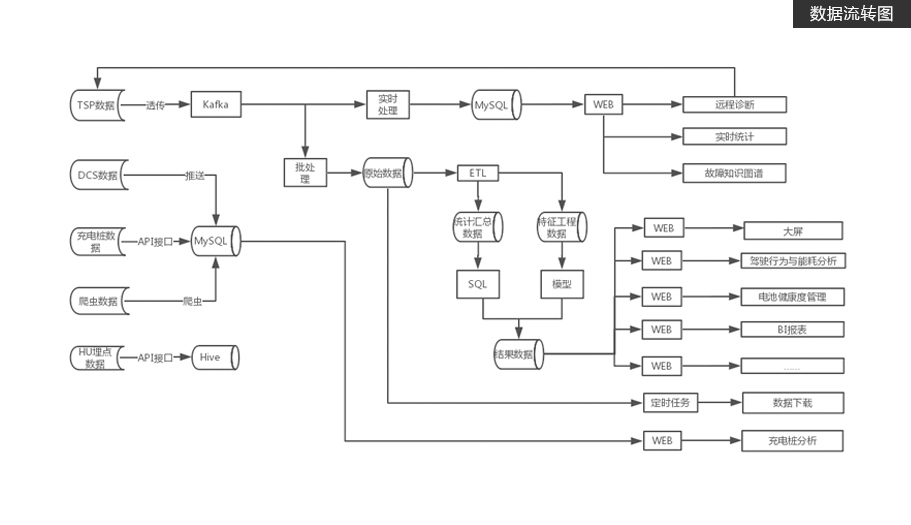
通过QBOX车辆终端数据收集,并解析为QSP数据、QCS数据、充电数据、HU数据
提供实时计算服务与离线计算服务,并通过API接口以报表和大屏展示分析结果数据项目特色
海量数据处理,系统15分钟内收集的新能源车辆的数据超过千万条
基于Hive、HBase、HDFS数据存储
基于Kafka数据传输
基于Flink全栈数据处理
基于Nginx做反向代理、LSV和Keepalived负载均衡和高可用 -
-
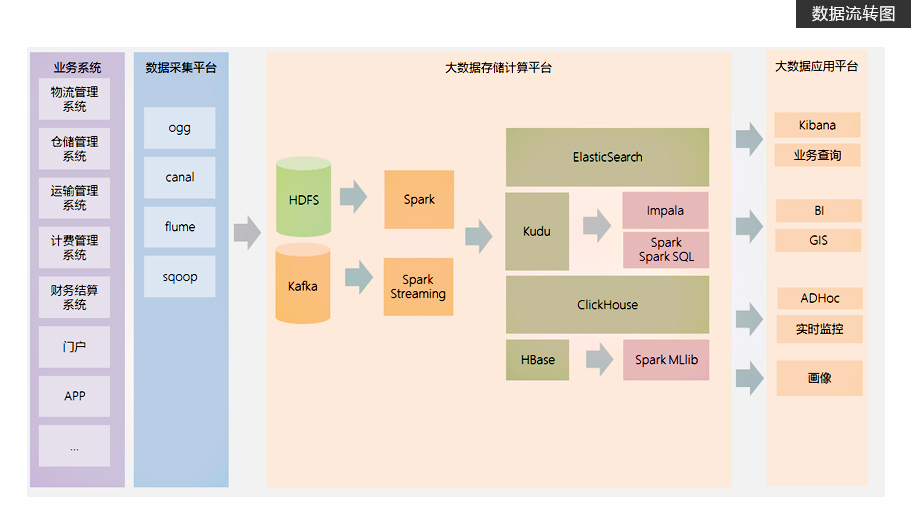
项目简介
基于一家大型物流公司研发的智慧物流大数据平台,日订单上千万
围绕订单、运输、仓储、搬运装卸、包装以及流通加工等物流环节中涉及的数据信息等
提高运输以及配送效率、减少物流成本、更有效地满足客户服务要求,并针对数据分析结果,提出具有中观指导意义的解决方案项目特色
涵盖离线业务、实时业务
ClickHouse实时存储、计算引擎
Kudu + Impala准实时分析系统
基于Docker搭建异构数据源,还原企业真实应用场景
以企业主流的Spark生态圈为核心技术,例如:Spark、Spark SQL、Structure Streaming -
-
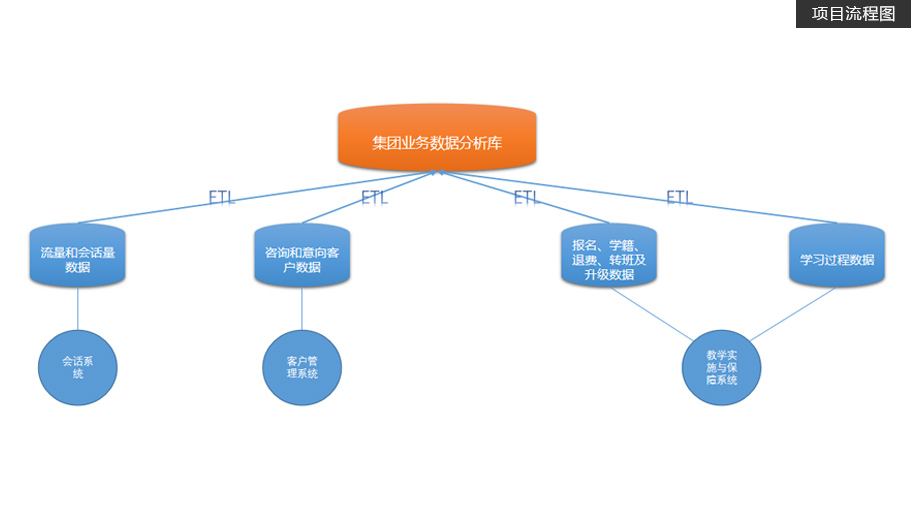
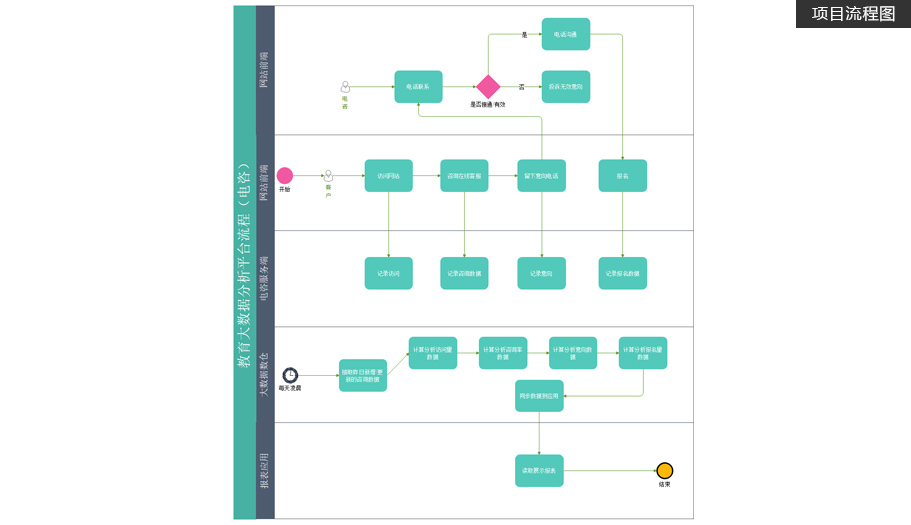
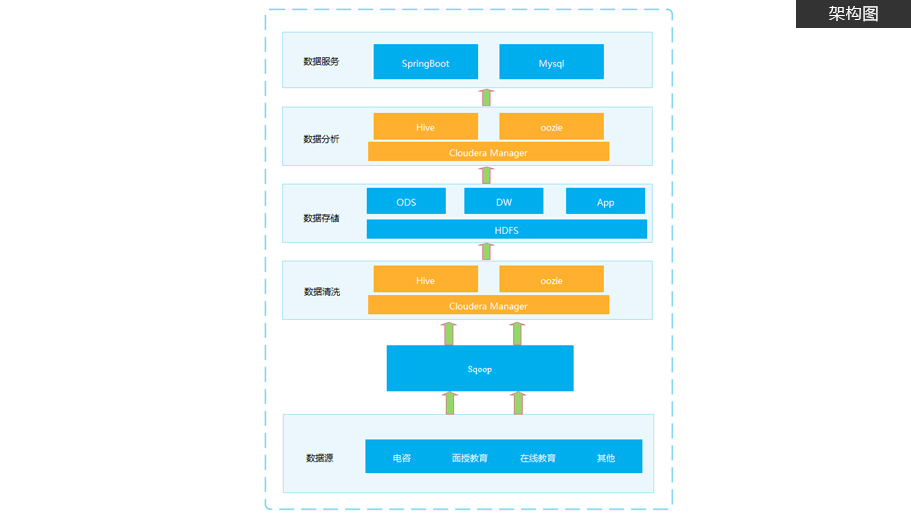
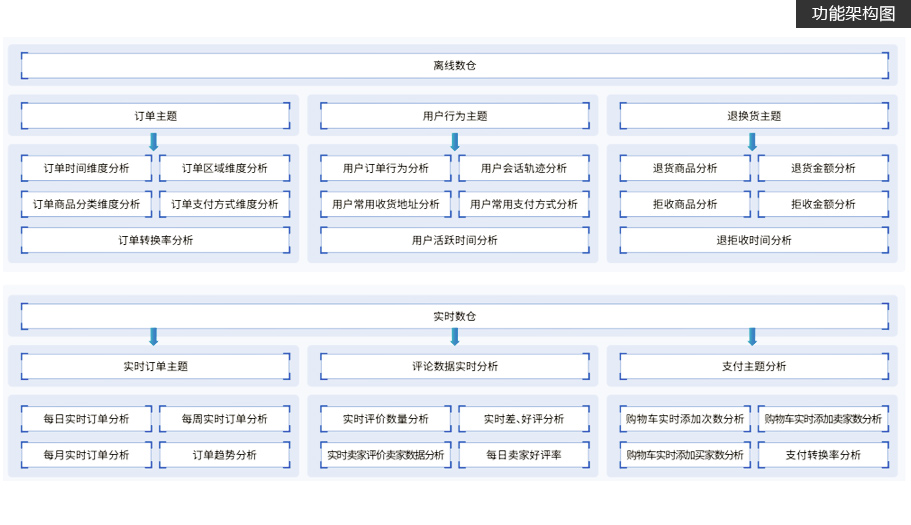
项目简介
建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理
项目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序
挖掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。项目特色
掌握离线数仓的分层与建模, 从需求、设计、研发、测试到落地上线的完整项目流程。
大量教育大数据的真实业务逻辑,共涉及20多个主题,100多个指标,提升学员在教育行业中的核心竞争力。
包括海量数据场景下如何优化配置、拉链表的具体应用、新增数据和更新数据的抽取和分析、hive函数的具体应用、
ClouderaManager可视化、自动部署和配置、Git、CodeReview功能。 -
-
项目简介
分析来自全品类B2B2C电商系统,以电商核心流程为主线进行数据分析,支撑运营
建立基于用户的全面分析体系,从多个维度建立基于用户的运营体系
实时分析用户访问流量、订单、店铺等运营指标项目特色
采用可Kettle同步MySQL数据采集方案; 采用JS埋点 + Flume实时用户点击行为数据采集方案
采用Spark on hive数据仓库解决方案; 采用Apache开源项目Superset可视化方案
采用Kylin交互式快速数据分析方案; 采用Canal进行MySQL业务数据实时采集方案
采用Flink对数据进行实时ETL处理解决方案; 采用Flink + Druid实时数仓解决方案
采用HBase + Phoenix明细数据实时查询方案; 采用开源平台Azkaban调度方案 -
-
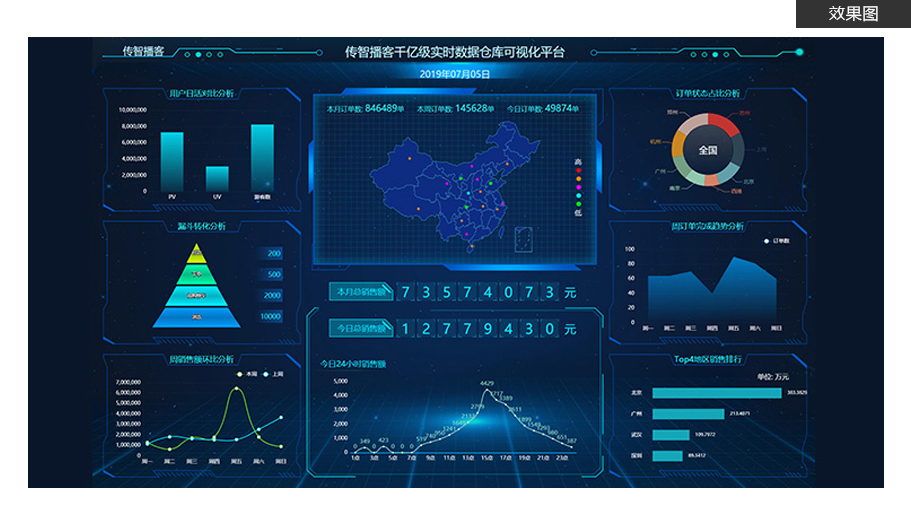
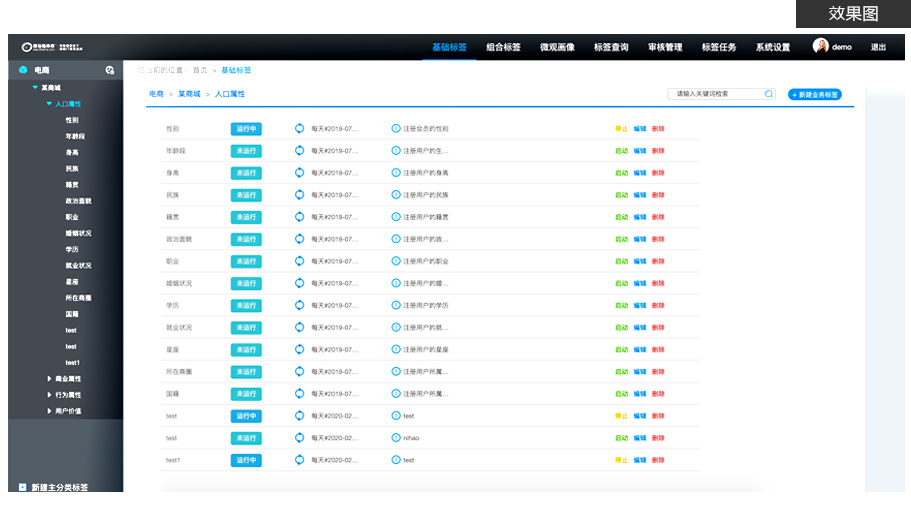
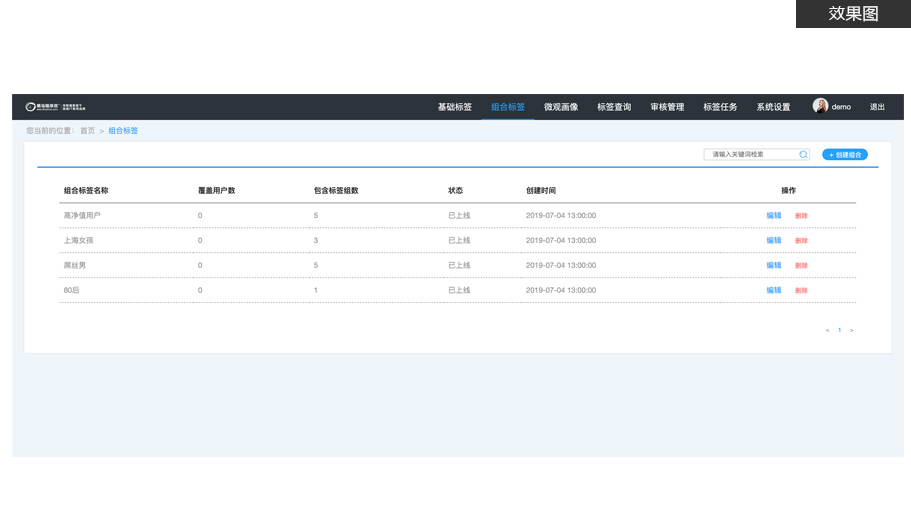
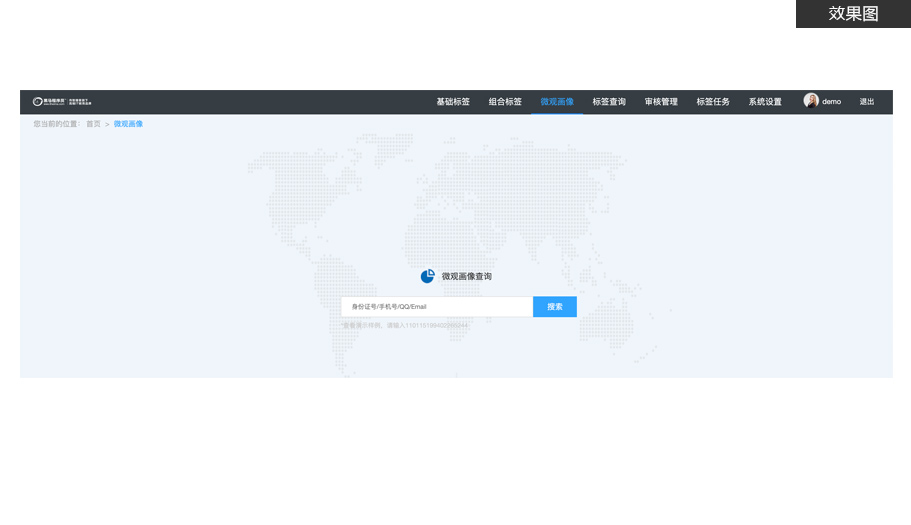
项目简介
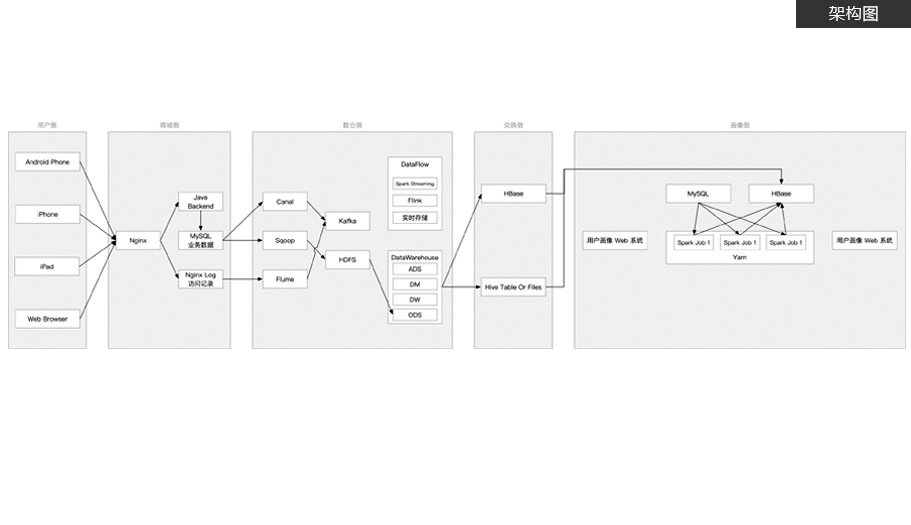
基于垂直电商平台构建的用户全方位画像,完整抽取出一个用户的信息全貌
业务围绕商品、订单、用户基础信息及行为信息等数据
实现用户和商品基础标签、组合标签、微观画像、标签查询等业务场景,提供了企业级多方位业务决策分析项目特色
采用 Spark 进行指标分析,并通过Spark MLLib建立数据挖掘模型
使用 HBase 存储标签数据
使用 CDH 管理集群
使用自动化脚本部署集群
使用 Oozie 搭建自动化提交平台 -
-
项目简介
限制伪装技术越来越强的爬虫访问和恶意占座行为,开发的大数据实时防爬工具
旅游行业和出行行业通用的防爬规则,提升行业竞争优势
完整高效通用的实时处理流程:数据采集、数据预处理、实时识别预警、离线分析
包含状态监控、反爬指标配置、运营指标监控展示等功能项目特色
使用Lua进行数据采集,实现并发量的最大化,降低高并发时的数据丢失
采用Kafka,实现各模块的解耦,利用Kafka的高吞吐和可持久化的特性为平台提升稳定性
利用Spark Streaming实现数据的实时计算,完成从数据预处理到爬虫黑名单的计算
Spark的状态监控功能,实时掌握Spark的运行状态
使用SparkSQL实现数据可视化相关指标的离线计算 -
-
项目简介
采用企业中真实的手机应用访问数据,找到广告系统中适应的人群,促进精准广告投放
建立用户画像系统,通过系统中的画像特征,筛选出符合广告主投放要求的用户
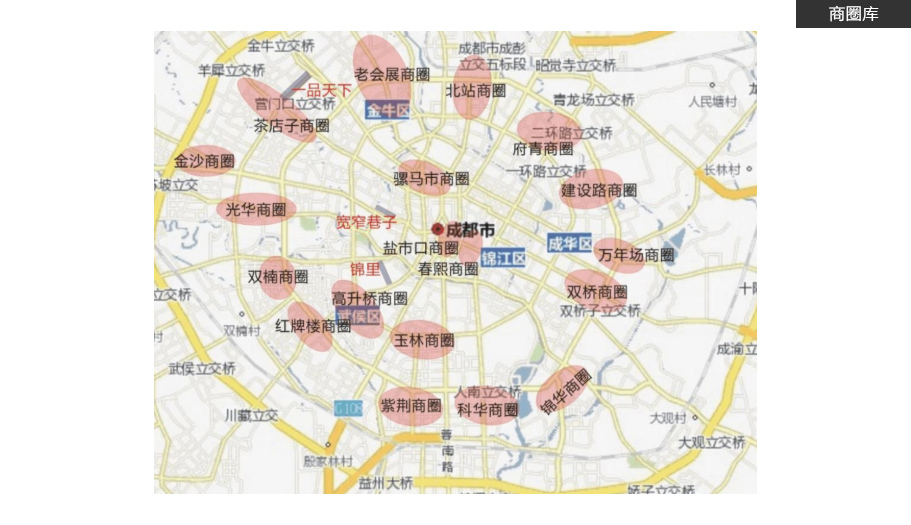
建立完整商圈库,通过商圈库确保广告在在各个城市商圈的有效投放项目特色
使用Apache Kudu作为核心数据存储
基于高德地图API打造自有商圈库,方便管理、更新
基于GraphFrames海量数据图计算
使用Zeppelin进行可视化查询与展示 -
-
项目简介
基于手机测速软件采集数据对手机网速、上行下行流量、信号强度等信息进行宏观分析
计算用户附近移动、联通、电信信号强弱、不同方位信号强弱
对比各家运营商提供有力的参考数据,如同一地标三家运营商信号强度项目特色
使用Echarts技术实现前端数据展示,与地图相关的报表使用百度地图提供的API。
实时接入mysql,不影响线上系统的正常使用,将数据发送到大数据平台
实时数据处理流程使用Canal+Flume+Kafka+SparkStreaming等技术
离线计算使用HDFS+Hive+Azkaban等技术 -










06.高级软件工程师课程 拓展职场升值必备技能
LESSON
高级软件工程师课程
- 大数据组件源码
深度解释 - 大数据数据结构
- 大数据运维
- 数据科学
- 直通大厂面试题
-
大数据数据计算
大数据数据存储
大数据数据采集
1-MapReduce核心源码解析
2-Hive核心源码解析
3-Spark核心源码解析4-Flink技术核心源码解析
5-Flink技术监控及调优
6-Yarn源码及性能调优1-Hbase核心源码
2-HDFS核心源码解析
3-Kafka底层源码解析4-Druid技术监控及调优
5-Elasticsearch源码解析及调优1-Flume核心源码解析
2-Cannel核心源码解析3-DataX核心源码解析
4-性能调优加强 -
分布式协调系统与
分布式通信原理及算法集群资源管理与调度算法
大数据常用的算法及数据结构
基础数据结构
1-序列化与远程过程调用框架
2-消息队列
3-应用层多播通信及Gossip协议4-Chubby锁服务
5-大数据组件的应用1-资源异质性与工作负载异质性
2-抢占式调度与非抢占式调度
3-资源管理与调度系统范型4-资源调度策略(调度器算法)
5-大数据组件的应用1-哈希分片(Hash Partition)
2-虚拟桶(Virtual Buckets)
3-一致性哈希(Consistent Hashing)
4-范围分片(Range Partition)5-布隆过滤器(Bloom Filter)
6-SkipList数据结构
7-LSM树
8-LZSS算法9-Cuckoo哈希
10-大数据组件的应用1-线性表、链表、堆栈、队列
2-树、二叉树及森林
3-图数据结构4-排序和查找算法
5-大数据组件的应用 -
集群运维监控
大规模集群快速部署
基础加强
1-Grafana监控
2-配置Grafana的zabbix数据源
3-内存buffer/cache/父子进程/swap/io队列等4-Docker容器+监控
5-Kafka监控/Yarm监控/Spark&Flink作业监控1-基于Linux系统的常用服务的安装配置,快速部署
2-基于Apache Ambari的Hadoop集群的供应、管理和监控3-Cloudera Manager部署
4-AWS的EMR部署1-Shell编程及Python语言加强
2- 掌握高级系统设置(SELinux、防火墙、DNS等)
3-性能调优加强 -
数据科学案例实战分析
数据分析方法论
统计学基础
基于实际业务场景案例结合数据分析与统计学完成数据科学案例全栈数据分析
1-数据分析六步曲
2-数据分析方法论(包括杜邦分析法、漏斗图分析法、矩阵关联分析法等 )
3-数据图表业务数据可视化及图表分析描述性统计、概率、离散型随机变量分布,连续型随机变量法分布、二元概率分布及抽样分布、假设检验、统计过程和质量控制
-
07.IT行业标杆讲师团队 传授解决问题能力
TEACHERS
-
人才筛选
-
技术考核
-
定制个人培训方案
-
教育心理学培训
-
教育方法培训

-
模拟教学
-
培训考核
-
培训结果验收
-
180天强化模式
-
正式授课
-
孟老师
对Hadoop、Spark、Flink等大数据体系有深入研究,有丰富的离线计算和实时计算经验。曾主导及参与空军总部装备信息化系统、国家卫星气象中心FY3C地面监测系统、用户画像系统、分布式爬虫系统、BI系统、历史数据在线查询系统、采集系统等项目的开发。
-
曹老师
阿里云大数据ACP专业认证工程师,多年大数据开发及教育培训经验,主导开发过房地产公司ERP系统、在线教育大数据分析平台、高校招生咨询大数据集成系统、电商推荐系统等项目。熟悉Java、Scala、Python等编程语言,擅长Spark、Hadoop、Flink等大数据主流技术。
-
张老师
专注于亿级用户规模的大数据平台研发建设和研发,历任项目经理、高级大牛、技术总监等职务,主导设计游戏一体化运营平台、通用大数据任务调度平台实现公司各部门集群资源共享、离线任务数据分析平台构建等,精通 C/C++、C#、Hadoop、Scala、Spark、Flink等有深入研究。
-
张老师
多年大数据技术经验,具有多年Hadoop、Flink、HBase、kafka、Redis、Flume、Spring Cloud等从业经验,先后服务于上交所、上海银行、中国邮政等,参与数据中心和电商平台的大数据及JAVA EE的平台设计和具体实施。
-
赵老师
人工智能领域技术大牛,多年模式识别和数据挖掘开发经验,主导研发多项国家和省级科研项目,专注ML/DL/PR/KG领域相关算法的应用,曾负责企业级信贷风控模型和智能医疗数据平台开发,对Hadoop、Spark、Tensorflow和PyTorch等大数据、人工智能技术有多年企业实践经验。
-
唐老师
从事多年互联网和大数据平台研发,主导和参与电商、医疗、通信等领域的项目开发,具有丰富的行业解决方案经验,对Hadoop、Kafka、Hive等大数据生态领域技术有深入研究。擅长教学和应用实践结合的方式为学员分享技术,驱动学员技术的应用性、思维的扩散性。
-
赵老师
从事多年爬虫与大数据开发与教学,对大数据的主流框架有着深入的理解,如hadoop、kafka、hive等,参与并主导的项目涉及分布式电商,数据爬取,离线分析等多个行业,授课逻辑严谨,条理清晰,注重学生独立解决问题的能力。
-
闻老师
高级互联网软件工程师,曾担任某物流公司CRM开发团队TL。多年大数据领域研发经验。擅长分布式开发和离线处理计算。对Hadoop、Flume、kafka、spark、ELK等大数据生态领域技术有一定的实践经验。
-
周老师
曾任IBM项目经理,主导IBM Platform KPI BI系统开发、e-support全球PMR智能调度分发系统开发;曾任国内大型中间件供应商,项目经理,主导国内最大的智能加油机供应商、大型锻造厂CRM、统一服务平台(ESB)项目研发、以及企业级BI项目。擅长Hadoop、Spark、Flink、Kylin、Druid等大数据技术有深入研究。
-
陈老师
多年大数据研发,担任过大数据工程师、项目经理、大数据架构师,曾主导企业级大数据平台建设和多项大数据项目研发,对Hadoop、HBase、Spark等大数据计算引擎深入理解以及项目实际经验。参与基于Flink的实时反欺诈风控、实时地铁故障预警等流式计算平台的设计和研发。
-
孔老师
先后在途牛旅游网、卓望集团等公司担任过经理、架构师和总监等职务。擅长服务端的高可用及性能提升,熟悉常见的开源框架、微服务治理及海量数据性能优化。曾负责和参与途牛旅游网的超级自由行、资源搜索等项目;负责江苏移动的家庭网络电视平台架构等。
-
李老师
多年开发和教学经验,精通C/C++,JavaEE,MySQL,Hadoop等技术,曾任职于中国电子科技集团公司第七研究所,担任高级研发工程师,曾参与移动公司RFID智能资产管理系统,中石油智能化数据分析系统等项目,讲课风格:幽默风趣、通俗易懂、深入浅出。
-
王老师
软件工程学士,熟练掌握Java,Android,大数据技术,专注于JavaEE企业级应用开发,曾主导研发河南省畜牧局OA,河南省地税局移动OA,中国移动渠道分析平台,审计署(郑州)内部考核自动化分析系统。
-
魏老师
多年资深大数据开发工程师经验,先后涉足Java、大数据、云计算等领域,熟悉大数据服务开发与云计算平台开发,专注于互联网APP后台数据统计、分析、建模等流程;熟悉车辆网领域云计算平台开发,拥有丰富的企业级大数据应用架构及开发经验。
-
孙老师
拥有5年大数据项目开发经验,参与过千亿级数据项目,精通hive、spark、flink等大数据开发工具。对技术一直抱有很大的热情,喜欢研究各种新技术。主张快乐学习,由浅入深,让学生轻松掌握课堂上教学的知识。
-
康老师
多年的项目研发与教学经验,具有丰富的企业级数据仓库和实时大数据开发经验。精通Greenplum等分布式关系型数据库,Hadoop大数据,Flink实时流计算等大数据软件开发及企业级数据仓库开发,曾供职于德邦公司、东风汽车子公司、宇信科技、易爱科技等企业,先后担任过高级软件开发工程师,项目架构师。
-
曹老师
高级大数据开发工程师,曾担任某互联网公司大数据部门TL。负责主导了多个0到1大数据平台的落地实施,并在其中担任主力研发人员。具有多年大数据领域和云平台研发经验,曾管理维护上PB级数据量的大规模集群,有海量数据的实际处理经验。精通Java、Scala、Python等多种开发语言。
-
江老师
具有多年大数据项目开发实战经验,先后参与过东南大学水声实验室、佳通、SPDB等不同行业的大数据平台的开发及实施,一直从事于HPC、云计算及大数据平台的研发,拥有丰富的大数据开发经验,对数据仓库、实时大数据平台、数据挖掘等领域有较深的研究。

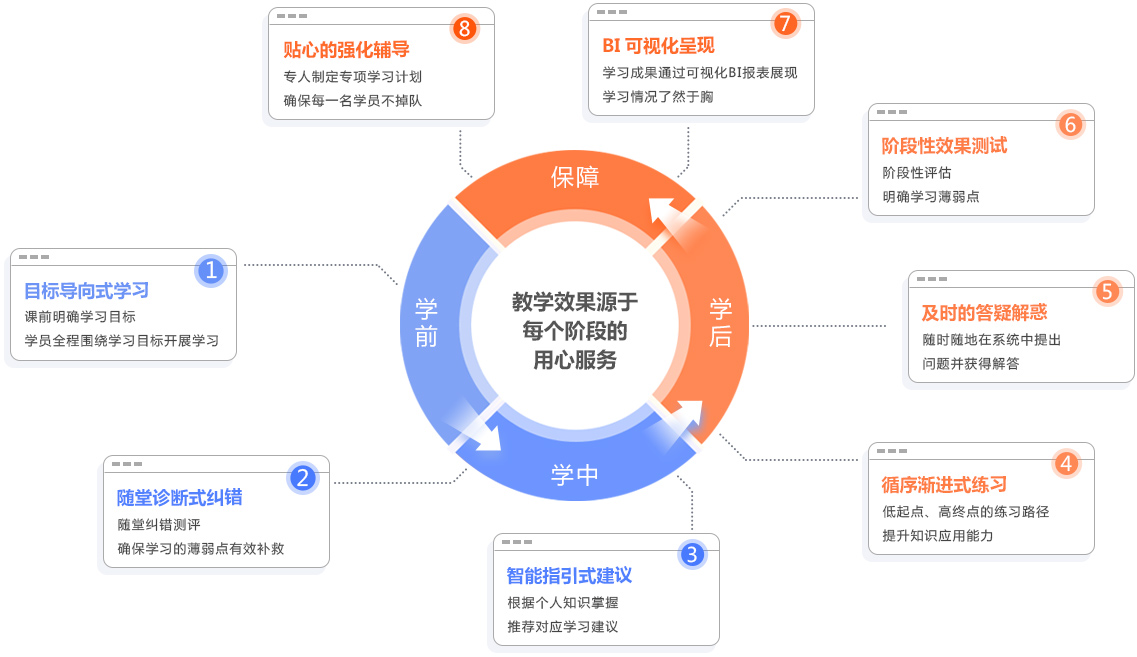
适合哪些人群学习?

-
应届大学毕业生
缺乏工作经验和技能,对未来没有明确的规划,期望通过学习大数据跻身IT行业的人员
-
预转行人员
目前工作待遇不理想,上升空间有限或已进入职业瓶颈期,想要突破转行的人员
-
大数据技术爱好者
有较强的思维逻辑能力,应对复杂业务场景处理,对大数据技术感兴趣的人员
-
有基础寻求提升
具有一定的大数据技术理论基础,需要了解大数据技术在实际业务中如何使用的人员
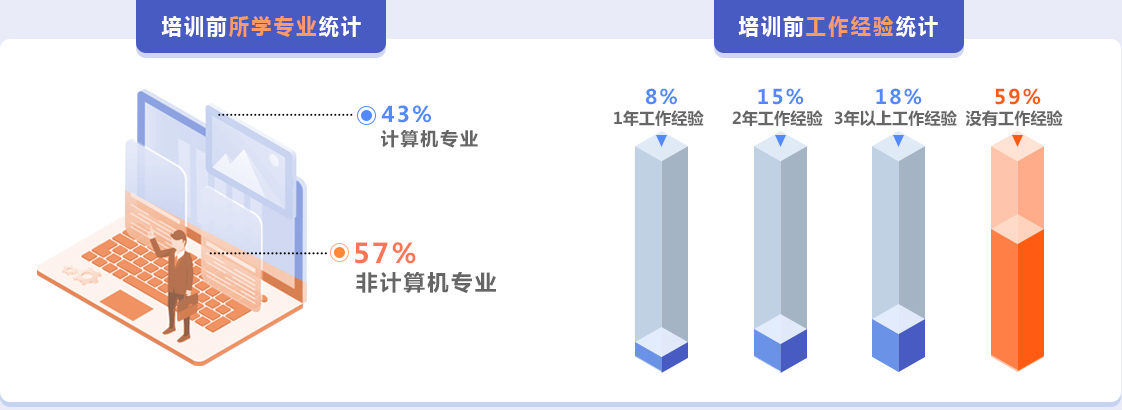
传智教育大数据学员构成
统计数据显示,无论你是非计算机专业或计算机专业,没有工作经验或有一定工作经验,都可以学大数据课程就业方向,是职业长远发展的起点
-

国家政策支持
大数据写入政府工作报告,被列入国家发展战略,助力中国经济从高速增长转向高质量发展 -

就业领域广泛
不管是传统领域,还是新兴领域,都需要大数据人才进行大数据的采集、分析、开发、应用等 -

人才缺口巨大
各大主流招聘网站信息年增长189%,大数据人才缺口巨大,十大高薪职业之一,供求比超过1:14

精英社区,助你打造IT职业生态圈




好口碑,学员更认可的大数据课程

2012年至今始终坚持以严谨态度对待教研教学,为学员提供高品质课程,用实力铸就好口碑!


